發布日期:2022-04-28 點擊率:40
C28x+FPU架構的C2000微處理器在原有的C28x定點CPU的基礎上加入了一些寄存器和指令,來支持IEEE 單精度浮點數的運算。對于在定點微處理器上編寫的程序,浮點C2000也完全兼容,不需要對程序做出改動。浮點處理器相對于定點處理器有如下好處:
編程更簡單
性能更優,比如除法,開方,FFT和IIR濾波等算法運算效率更高。
程序魯棒性更強。
一、IEEE754格式的浮點數
C28x+FPU的單精度浮點數遵循IEEE754格式。它包括:
1位符號位:0表示正數,1表示負數。
8位階碼
23位尾數
31 | 30 23 | 22 0 |
符號位 | 階碼 | 尾數 |
表1:IEEE單精度浮點數
符號位S | 階碼E | 尾數M | 值 |
0 | 0 | 0 | 正0 |
1 | 0 | 0 | 負0 |
0或1 | 0 | 非0 | 非規格化數(1) |
0 | 1-254 | 0x00000-0x7FFFF | 正常范圍正數(2) |
1 | 1-254 | 0x00000-0x7FFFF | 正常范圍負數(2) |
0 | 255 | 0 | 正無窮大 |
1 | 255 | 0 | 負無窮大 |
0或1 | 255 | 非0 | 非數值(NaN) |
(1)非規格化數值非常小,計算公式為(-1)sx2(E-126)x0.M
(2)正常范圍數值計算公式為(-1)sx2(E-127)x1.M
正常范圍數值落在± ~1.7 x 10 -38 to ± ~3.4 x 10 +38范圍內。從表1可以看出,IEEE754標準包括:
標準數據格式和特殊值,比如非數值(NaN)和無窮大
標準舍入模式和浮點運算
多平臺支持,包括德州儀器C67x系列芯片。
C2000對該標準作了一些簡化:
狀態標志位和比較運算不區分正0和負0
非規格化數值被認為是0
對非數值(NaN)處理方式和無窮大一樣。
IEEE754標準有5種舍入模式,C28x+FPU只支持其中兩種:
--截斷:小數位不管大小全部舍去
--就近舍入向偶舍入:這種模式下如果小數位小于5就舍去,大于5就進位,如果小數位為5,則舍入到最近的偶數。
表2展示了不同的舍入模式對數據的影響。C28x+FPU編譯器默認將微處理器配置為就近舍入向偶舍入模式[1]。
表2:不同舍入模式示例
模式 / 實際值 | +11.5 | +12.5 | ?11.5 | ?12.5 |
就近舍入向偶舍入 | +12.0 | +12.0 | ?12.0 | ?12.0 |
就近舍入遠離0舍入 | +12.0 | +13.0 | ?12.0 | ?13.0 |
截斷 | +11.0 | +12.0 | ?11.0 | ?12.0 |
向上舍入 | +12.0 | +13.0 | ?11.0 | ?12.0 |
向下舍入 | +11.0 | +12.0 | ?12.0 | ?13.0 |
二、浮點C2000芯片運算技巧和注意點
浮點數的精度由尾數位決定,絕大多數的數在用浮點數表示時都會有誤差,這些誤差很小,多數情況下可以忽略,但是在經過多次計算后這個誤差可能會大到無法接受。
下面用實例來進行說明,下面一段代碼定義float類型變量,分別在TI最新的Delfino芯片F28379D的CPU1和CLA1上,將11.7加20001次。
float CLATMPDATA=0;
int index=20001;
while(index--)
{
CLATMPDATA=CLATMPDATA+11.7;
}
得到如下結果:
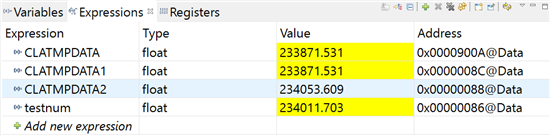
其中CLATMPDATA1是在CLA中將11.7加20001次得到的結果,CLATMPDATA2是在CPU中將11.7加20001次得到的結果。可以看出兩者所得到的結果不同,并且都和正確結果234011.7有較大差距。
為何CPU和CLA計算結果不同?
CPU和CLA運算結果的不同是由于其對浮點數的舍入模式的不同造成的,前文已經說過,C28x+FPU 編譯器默認將CPU配置為就近舍入向偶舍入模式。而CLA不同,CLA默認為截斷舍入模式[2]。在CLA的代碼中,我們可以通過增加下述代碼:
__asm(" MSETFLG RNDF32=1");//1為就近舍入向偶舍入,0為截斷舍入
將CLA的舍入模式更改為就近舍入向偶舍入模式,然后再運行代碼,可以得到和CPU同樣的結果。

2. 為何CPU和CLA計算結果都有較大誤差?如何解決?
11.7在用IEEE754格式的浮點數表示時為0x413b3333,其對應的實際值為11.69999980926513671875,可以看出誤差很小,但是經過多次累加多次舍入后得到的結果誤差較大,對此,我們可以將CLATMPDATA定義為long double型變量(64位),再次運行相同的代碼,可以得到如下結果,可以看到誤差很小可以忽略。

需要指出的是,現有的C28x CPU只支持單精度(32位)的硬件浮點運算,對于64位雙精度浮點數的運算都是通過軟件實現的,所以其運算速率會慢很多。另外CLA不支持64位數。
在這個實例中,我們可以分別觀察float類型變量和long double類型變量的匯編代碼如下:
C code: CLATMPDATA2=CLATMPDATA2+11.7;
如果CLATMPDATA2是float型變量,則相應的匯編代碼為:
00c08d: E80209D8 MOVIZ R0, #0x413b 1cycle
00c08f: E2AF0112 MOV32 R1H, @0x12, UNCF 1cycle
00c091: E8099998 MOVXI R0H, #0x3333 1cycle
00c093: E7100040 ADDF32 R0H, R0H, R1H 2cycle
00c095: 7700 NOP 1cycle
00c096: E2030012 MOV32 @0x12, R0H 1cycle
如果CLATMPDATA2是long double型變量,則相應的匯編代碼為:
00c08b: 7680005A MOVL XAR6, #0x00005a 1cycle
00c08d: 8F00005A MOVL XAR4, #0x00005a 1cycle
00c08f: 8F40C26A MOVL XAR5, #0x00c26a 1cycle
00c091: FF69 SPM #0 1cycle
00c092: 7640C0C9 LCR FD$$ADD 4cycle(跳轉耗時)
+25cycle(FD$$ADD函數內部需要25cycle)
可以看出CPU對float類型數執行一次加法耗時7個cycle,對long double類型數執行一次加法耗時33個cycle。
三、結論
1. C2000的CPU和CLA默認的舍入模式不同,在計算浮點數時可能會得到不同的結果,但是我們可以通過代碼改變其舍入模式得到相同的結果。
2. 單精度浮點數經過多次計算后可能會有較大誤差,可以通過將變量定義為64位long double型解決精度問題。
3. C28x CPU只支持單精度(32位)的硬件浮點運算,對于64位雙精度浮點數的運算都是通過軟件實現的,所以其運算速率會慢很多。在下一代的C2000產品中我們會實現對64位雙精度浮點數運算的硬件支持。
References
[1]. TMS320C28x FPU Primer (SPRAAN9A)
[2]. TMS320F2837xD Dual-Core Delfino Microcontrollers Technical Reference Manual (SPRUHM8F)
下一篇: PLC、DCS、FCS三大控
上一篇: 一種使用分立邏輯芯片